
Target: Host
Previous Status: Green
New Status: Red
Alarm Definition:
([Event alarm expression: vSphere HA agent on a host has an error; Status = Red] OR [Event alarm expression: vSphere HA detected a network isolated host; Status = Red] OR [Event alarm expression: vSphere HA detected a network-partitioned host; Status = Red] OR [Event alarm expression: vSphere HA detected a host failure; Status = Red] OR [Event alarm expression: Host has no port groups enabled for vSphere HA; Status = Red] OR [Event alarm expression: vSphere HA agent is healthy; Status = Green])
Event details:
vSphere HA detected that host (host) is in a different network partition than the master (Cluster) in Datacenter
I had been getting this message randomly over the last couple months on some of my datacenter hosts. These alerts didn’t seem to be causing any problems within the cluster, but I wanted to get to the bottom of this. I opened a ticket with VMware and uploaded the logs from both the host and vCenter, but they didn’t see anything out of the ordinary. On the second webex with VMware I noticed a couple strange things with the management network that might be the cause.
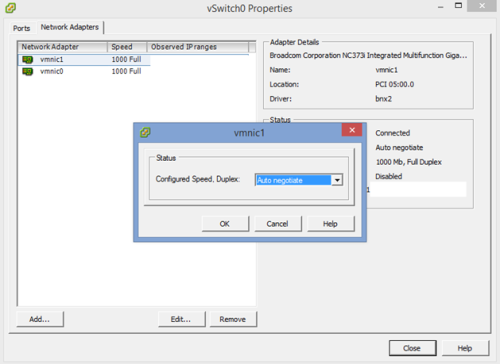
- The first thing I noticed was that the NICs were set for “Auto Negotiate”. I originally set up our environment on ESXi 4 before upgrading to ESXi 5.1. When I initially set this up I hard coded (KB1004089) these to 1000GB/Full. I am wondering if at some point during the upgraded that they defaulted back. On our switches it was set at 1000GB/Full so it is important that we set this on the host NICs to 1000GB/Full as well.
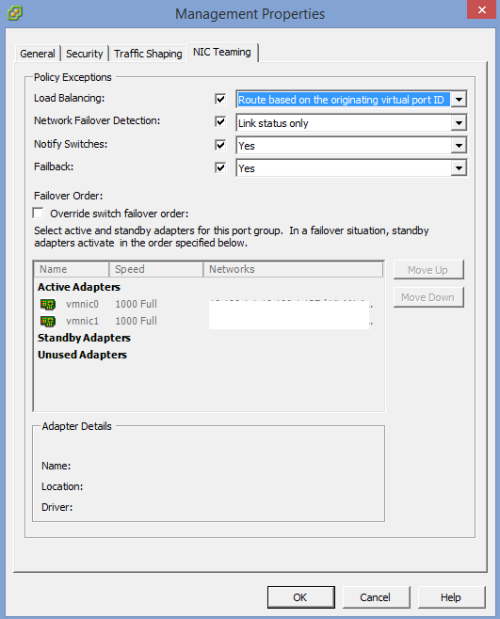
- The second thing that I noticed that in the Management network that I had the Load Balancing set to “Route based on IP hash”. The problem here is that for this to work correctly you need a port channel configured (I do not have this configured this way). This might be the cause of the HA problem if the traffic is going across these NICs is getting confused because of the Load Balancing configuration. I changed this to “Route based on the originating virtual port ID”, which makes the traffic go out on the port that it came in on. There is a good read found here…http://blogs.vmware.com/kb/2013/03/troubleshooting-network-teaming-problems-with-ip-hash.html.
This case is still ongoing with VMware and I should know in the next couple weeks if this solves my problem; my gut tells me it will.

Adding a reply from Google + user Ryan Marx:
We have also seen this issue. It turned out to be an issue with our core routing through the the switches CPU. Once that was resolved we did not see this message anymore. You could also setup multiple isolation response addresses. By default it only pings the gateway of the host. If you add in the next hop address it will ping both addresses and help prevent false positives.
I noticed a large amount of latency and chatter on our management network for the past few days. Before then it was sleeping, little to no data. I used SolarWinds to keep tabs on it. You can also use PRTG or something like it to accomplish the same thing. That prompted me to engage our network team to take a deeper look at the network In doing so they noticed issues with other systems as well. The extra latency in the management network would sometimes prevent HA heartbeat responses from returning to the hosts.
my servers – two hosts – are showing up those messages as well, Vmware told me to check the Etherchannel configuration in our external Switch and also Blade Chassis, but the configuration we using is the same in 5 more countries and only one is having this messages also I losing a lot of pings on this two ESXi 5.5. servers, the only thing left is to update the Blade Network Switch which I know won’t help, but Vmware does not what is causing the issue
Do you have vSphere Enterprise Plus licenses for your hosts? If so, on one of your working hosts you could use host profiles to take your good configuration and compare it to the host that is having problems.
yeah that’s a good idea you know, yes we’re using Ent Plus
i have the same problem. i’ll try your “solution”
Let me know if it works for you!
It’s been several months since the last comment. I have 3 identical hosts. 2 have been working great since installation. The 3rd is having the issue with vSphere HA. Has anyone found a solution? Nobody posted any results of the “solutions” provided.
I am sorry, I do need to add to that post that since I made these changes, the messages went away. Are you actually experiencing a problem with HA or is it just alerting that there was an error?
Thanks for the reply. As I mentioned, we have 3 hosts in the cluster that are identical. I just took over as the Systems Manager and since they got the servers up with VMWare, the one has been giving them issues with the vSphereHA host status goes from Green to Red several times a day. The prior Systems Manager didn’t want to troubleshoot it, so it’s been in Maintenance Mode with no VM’s on it. Now, I want to find the cause. So basically I don’t know if there’s an actually problem but in the events it’s an alarm. We have 30 VM’s currently with 19 on one host and 11 on the other. I can’t put any used VM’s on the bad host for fear that if something happens it won’t migrate to a good host. I did create a new VM and it says on the host even when the HA agent is in the Network Partition State. I am not familiar with VMWare enough to know how to actually test the HA. One thing I did test was all 8 of the NIC ports to see if it was a hardware issue with the NIC ‘s (4 onboard and 4 on the adapter). The alert occurs on all 8 ports. It’s not the switch since all 3 hosts are connected to the same switch. I have checked the settings of the 2 good hosts with all the settings on the 3rd and they are all configured the same. I’m not sure where to look next. Any suggestions would be greatly appreciated.
Rick, I would first check to make sure that Networking for VMware (Speed/Duplex) is the same on both VMware and your networking equipment and then go from there. What is your version of vSphere?
The switches are set to 1000 Full Duplex and the network adapter configuration in vSphere is set to Auto Negotiate and connect at 1000 Full. We are using vSphere 5.5.
You want to make sure that you either set everything on both sides to auto/auto or make sure that if on your switches it is set to 1000/Full that in vmware it is set to 1000/Full as well. I would start there. After making this change I would turn off HA and then back on. This should not cause any issues on your cluster, but please do it after hours just to make sure if you are not comfortable doing that.
This is what is weird about the issue. I will use vm1 and vm2 as hosts that are working and vm3 has the issues. I checked every setting on vm1 and vm2 and made sure vm3 had the same settings. I came in this morning and HA went to Network Partition (Alarm ‘vSphere HA host status’ on vm3 changed from Green to Red) 5 times. Each time it was in alarm for exactly 20 minutes except one was 40 minutes. 4:50-5:10pm, 5:50-6:10, 7:30-8:10, 4:10-4:30am, 5:30-5:50am. It’s strange that they are increments of 20 minutes and they all start in 10 minute increments of the hour. There are no 4:52 or 8:27. Also I got vSphere HA agent on this host could not reach isolation address: x.x.x.x errors. This occurred 10 times during the night. All for exactly 15 minutes and all starting at similar times – 7:55, 8:35, 11:35, 12:15, 12:55, 1:35, 2:15, 3:35, 4:15, and 4:55. And no errors since 5:50am this morning. I was trying to establish a pattern. I don’t know if VM does timing cycle on when it checks the status of it’s connections or what.
You made that network change for all three hosts and on the switch side to either auto/auto or 1000/Full on everything?
The NIC’s are set to auto negotiate and I just checked the switches and they are set to auto negotiate also.
Rick, I came through same issue today and wondering what have you done to fix it. My nics are set to auto negotiate on both host uplinks and as well as upstream switches.